Now you might wonder when reading this title why would you want want to be offline? Truth is, I'd wish i was online everywhere, that would save me a lot of manual work! However even in an era with such an abundance of Internet, it is not always possible or practical to synchronize data across the Internet. While being online makes a lot of computer work easier i also like to be offline at certain times, makes you more creative or resourceful. You might just grab a book instead of reading something online, maybe even do something entirely different, like repairing a bicycle in the shed. 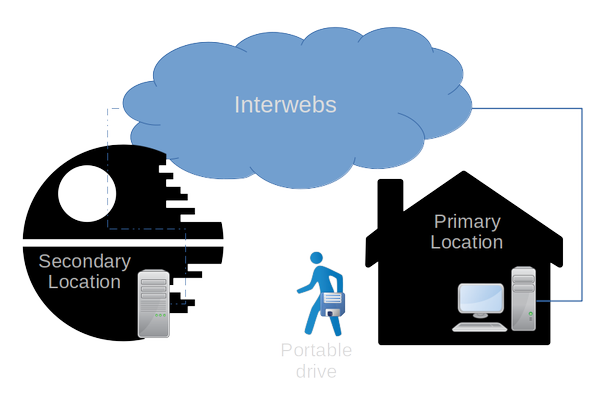 Oh Internet where art thou!?I have two locations with one of them having an erratic Internet connection, besides that it has a daily data limit. The primary location has a fast and stable internet connection, which is where i run most of my projects. However i also need these files at the secondary location, but they are very large; 3TB’s total, growing daily. The second location functions as a backup and testing ground for some projects but hardly any new data is created here. However to keep the locations synchronized i would have to bring the hard drives or entire system from the secondary location to the primary every time new material is available, highly impractical i'd say ;-). So i settled on a portable thumb drive, which (of course) does not have the capacity of the servers. Now that really makes a shitty situation all together, no way of synchronizing directly and limited space to move data... perfect. Now I could of course have a larger portable drive, you know, those 3.5 inch ones. This would technically solve the problem, but my behavior is more difficult to change, i'd just forget the damn thing get annoyed by the weight, drop it, and what not. They're just too cumbersome and fragile in my opinion for daily (ab)use. While fast and stable internet is actually available at the second location for a 'mere' 300 Euro's per year, i'd rather invest that budget in something more useful. There just must be another way. Synchronizing with this scenario offers various software solutions, i could use a proper backup program or a synchronizing tool. Backup programs would be interesting because of their feature to incrementally backup files. Inevitably though, I would run out of space on my portable drive unless I create a new restore point (from which incremental backups start again). With a synchronizing tool I can easily mirror two data sets, however none (that I have come across) can synchronize incrementally. Automatize (and get paranoid)So before i talk about any automation let me state that i am extremely paranoid in situations where automation and data are combined. You DO NOT WANT data loss! Automation can always behave in an unforeseen way and thus possibly destroy data, since this automation also runs on the primary data location i need some manual actions for now (until i find a safe solution). At first I synchronized specific folders that I needed with FreeFileSync, it’s a nice tool that has the option to mirror specific data locations. Although very safe, this got boring quickly. I realized that a more common tool on Linux called rsync provides an option to ignore file size or actual data so to say, this gave me an idea. What if I could just generate a file structure of the secondary location (backup)? I could put that on the portable drive and then mirror the new data at the primary location (source) without the need for a large portable drive (since only the data added from the source would actually contain data). As it turns out this is easily done on Linux with a simple command: cp -a --attributes-only Dir1 Dir2So, I made a simple script that is able to make an empty copy of a directory you would like to keep synchronized (mirrored): #!/bin/bash # create_sync_base.sh # Version: 1.0 # Author: Jochum Döring, jochum (dot) doring (at) gmail (dot) com # License: CC BY-SA # About: This script will make copies of a given folder without copying actual data. function yes_or_no { while true; do read -p "$* [y/n]: " yn case $yn in [Yy]*) return 0 ;; [Nn]*) echo "Aborted" ; return 1 ;; esac done } SOURCEDIR="/mnt/DATA/project-deathstar/" DRIVENAME="TRANSPORT" SYNCDIR="SYNC" if grep -qs '/run/media/'$USER'/'$DRIVENAME'' /proc/mounts; then yes_or_no "$msg Target disk found, continue?" && if [ -d "/run/media/$USER/$DRIVENAME/$SYNCDIR/" ]; then echo "Cleaning sync directory" rm -rf /run/media/$USER/$DRIVENAME/$SYNCDIR/* echo "Done" echo "Now building sync base..." cp -a --attributes-only $SOURCEDIR /run/media/$USER/$DRIVENAME/$SYNCDIR/ echo "Finished!" else yes_or_no "$msg SYNC directory does not exist! Create it?" && mkdir /run/media/$USER/$DRIVENAME/$SYNCDIR echo "Done" echo "Now building sync base..." cp -a --attributes-only $SOURCEDIR /run/media/$USER/$DRIVENAME/$SYNCDIR/ echo "Finished!" fi else echo "Target not found, exiting." fi When the fake copy is generated we can let rsync do its work at the primary location, like so: rsync -r -t -v --progress --delete --ignore-existing --modify-window=1 -l -H -s $SOURCEDIR /run/media/$USER/$DRIVENAME/$SYNCDIRAnd on the secondary side simply the other way around: rsync -r -t -v --progress --delete --ignore-existing --modify-window=1 -l -H -s /run/media/$USER/$DRIVENAME/$SYNCDIR $SOURCEDIR
I can already hear the fanatic rsync users say, why not just use the --dry-run and --log-file options that rsync has built in instead of using this script?Ah yes, well here's the problem with that: By default rsync does not provide any information about the files except the name and location. There are options to do that, i know, but it required lots of reading in manual pages and i was too impatient at the moment ;-) In the end this command did what i needed, but i will definitely use rsync for this later on if the current concept is proven to work on a daily basis. How do i...?You run this script on the backup location, this creates a base structure which you can then compare against the primary location (source) with rsync.It might even possible to synchronize the backup side to the source but only by date/time stamp. A bit too scary for my taste, I would need an option to check for any data to be overwritten to have a size larger than 0. I haven’t figured that out yet so I currently only mirror data from the source to the backup location. Conclusion & LimitationsAll in all, this at least saves me some time, I will probably automate this more in the future depending on how annoyed I get by all the manual labor ;-) My plans are to further develop the script in stages, stage one and two having been realized at this point. Limitations As handy as the current script is, it has a serious drawback: It can only check if a file exists on the secondary location, but not the file's size or date. This does not hurt the primary side, however any data that is modified or damaged on the secondary location goes undetected. This was of course the nature of this script: to mirror data in one direction without having actual data. Ultimately though, if by some error files get overwritten with empty ones it won't be noticed in the sync process, this is why i added the MAX_EMPTY_FILES variable in the second stage of the script. This way there is at least some basic way to check for inconsistency in the data, when this value is reached however this could already mean that shit hit the fan. Luckily rsync (by default) does delete files in a safe way, by moving them to trash. Another limitation at this stage is that data can only be mirrored. It would of course be a desirable feature for any synchronizing tool to actually be able to synchronize properly. As far as i could tell rsync should be able to make this possible with the help of custom log files (read automatize), but this is quite elaborate and thus something to look into later on in the development. Planned roadmap
|
Software >